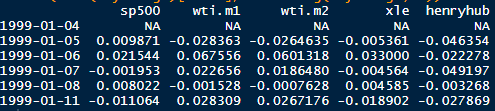
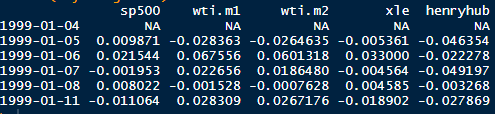
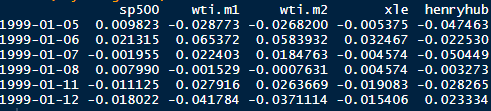
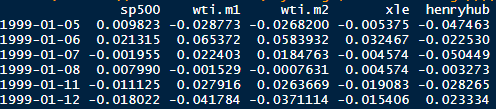
dS = μSdt + σSdW is an Ito process with drift µ and diffusion W. The instantaneous change in W, dW, is a Brownian motion scaled by a constant σ. The increments of dW are normally distributed with mean 0 and standard deviation 1.
In Ito calculus, dt and dW behave like this when multiplied:
dWdW = dt
dtdW = 0
dtdt = 0
This means that
(dS)² = σ²S²dt.
If C is an option and S is its underlying asset then, applying Ito’s lemma and collecting terms, we get:
dC = (∂C/∂t)dt + (∂C/∂S)dS + ½(∂²C/∂S²)(dS)²
dC = (∂C/∂t)dt + (∂C/∂S)( μSdt + σSdW)
+ ½(∂²C/∂S²)σ²S²dt
dC = (∂C/∂t)dt + (∂C/∂S) μSdt + (∂C/∂S)σSdW
+ ½(∂²C/∂S²)σ²S²dt
dC = [(∂C/∂t) + μS(∂C/∂S) + ½(∂²C/∂S²) σ²S²]dt
+ (∂C/∂S)σSdW,
which is the change in the option’s value over small increments of time.
The first term, called an infinitesimal operator, has a standard, Newtonian derivative,dt, and the dW term has a stochastic, or random, derivative. To create a riskless position, the random term must be hedged away.
A position of one option and Δ shares of S is created, since all changes in the option’s value depend on changes in S. The portfolio is
Π = C + ΔS
The change in the portfolio’s value is
dΠ = dC + ΔdS.
Substituting dC and dS from above gives:
dΠ = [(∂C/∂t) + μS(∂C/∂S) + ½(∂²C/∂S²) σ²S²]dt + (∂C/∂S) σSdW + Δ[μSdt + σSdW]
and
dΠ = [(∂C/∂t) + μS(∂C/∂S) + ½(∂²C/∂S²) σ²S²]dt
+ (∂C/∂S) σSdW + ΔμSdt + ΔσSdW
Set
(∂C/∂S) σSdW + ΔσSdW = 0
to get rid of the random terms. This means that (∂C/∂S) = -Δ, and the risky terms cancel each other out, leaving
dΠ = [(∂C/∂t) + ½(∂²C/∂S²) σ²S²]dt
as the portfolio’s change in value under small changes in time. The portfolio is riskless now, so it has an expected growth of r, meaning
dΠ = rΠdt = r(C + ΔS)dt = r[C – (∂C/∂S)S]dt
Setting
r[C – (∂C/∂S)S]dt = [(∂C/∂t) + ½(∂²C/∂S²) σ²S²]dt
and cancelling terms gives
rC = (∂C/∂t) + r(∂C/∂S)S + ½(∂²C/∂S²) σ²S²
which is the Black-Scholes-Merton differential equation, a 2nd order parabolic partial differential equation. Notice that μ, the drift of the underlying S, is not in the equation. The only drift term is the risk free interest rate r.
Replacing each partial differential with its corresponding Greek letter gives
rC = Θ + rSΔ + ½ σ²S² Γ
where
∂C/∂t = Θ
∂C/∂S = Δ
∂²C/∂S² = Γ